Object Perception and Manipulation
To comprehend the environment, robots must first model individual objects from multiple perspectives, including their 2D visual appearance, 3D geometry, and interactive spatial positioning. For more information, please click each image below the paragraphs.
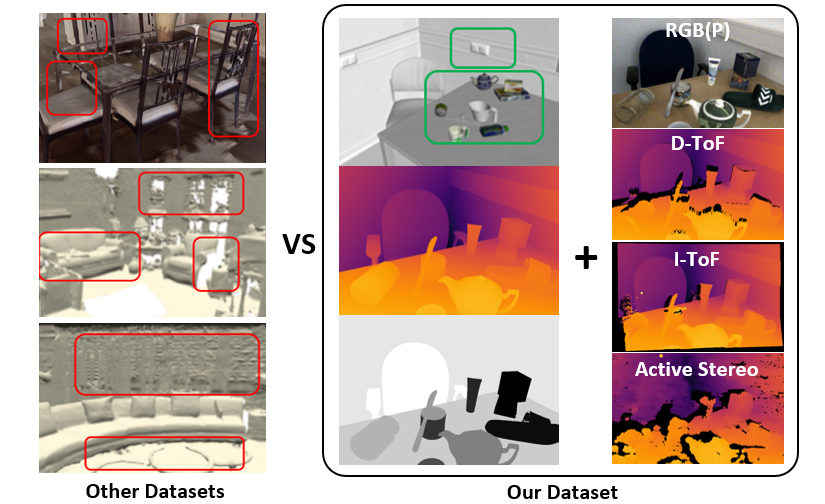
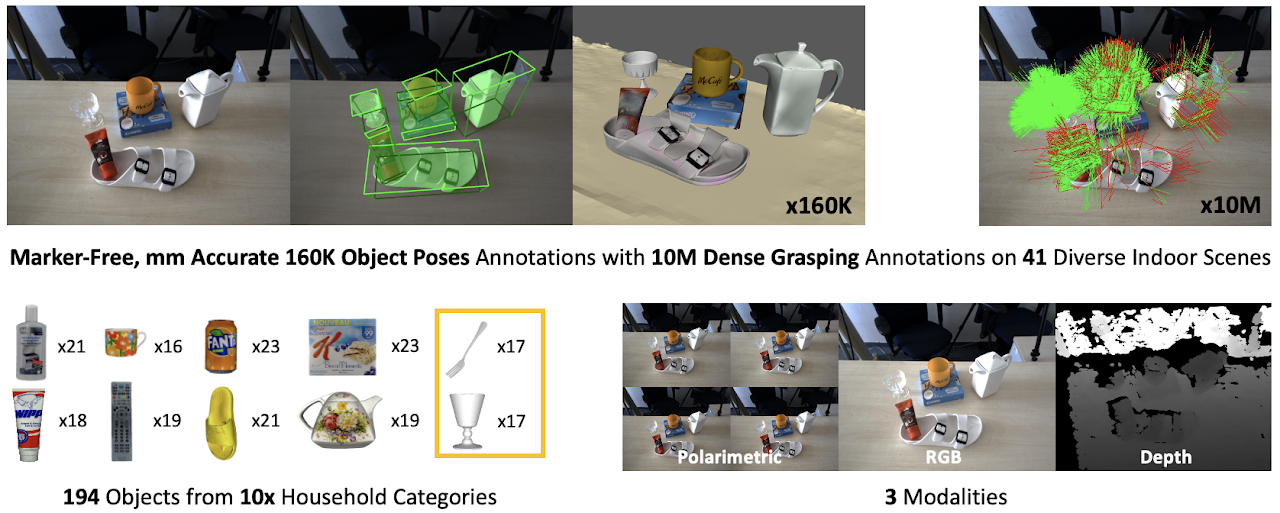
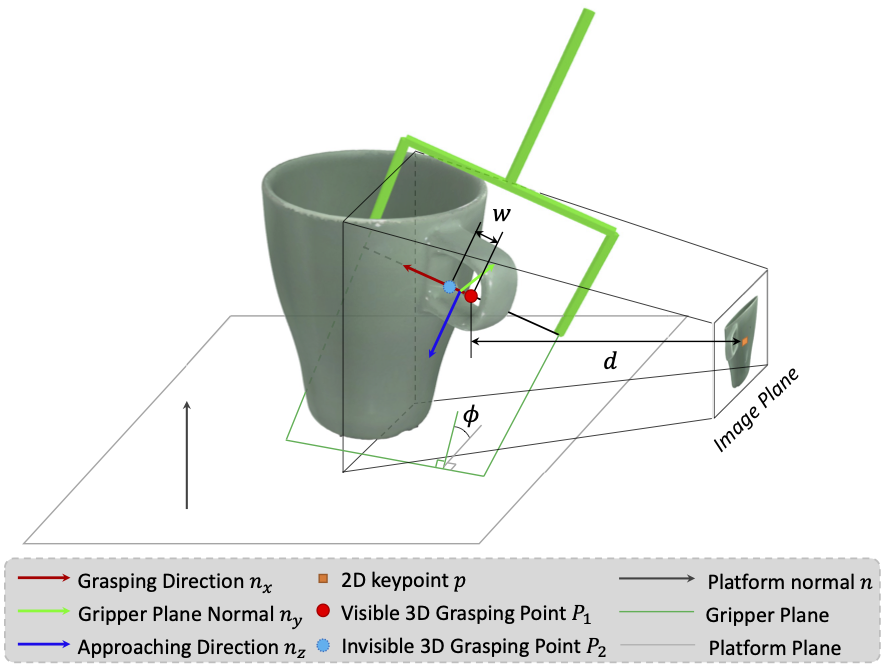
For this purpose, we collect large-scale datasets, HAMMER and HouseCat6D, for novel view synthesis, depth estimation and object/grasp pose estimation.


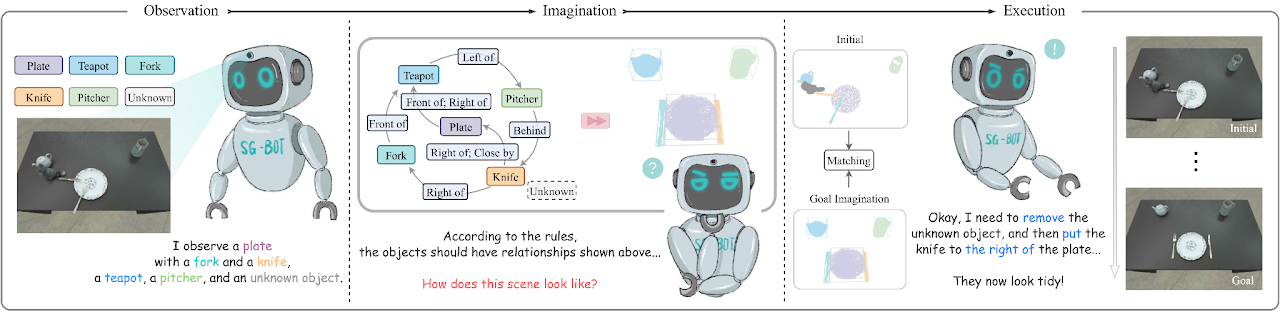
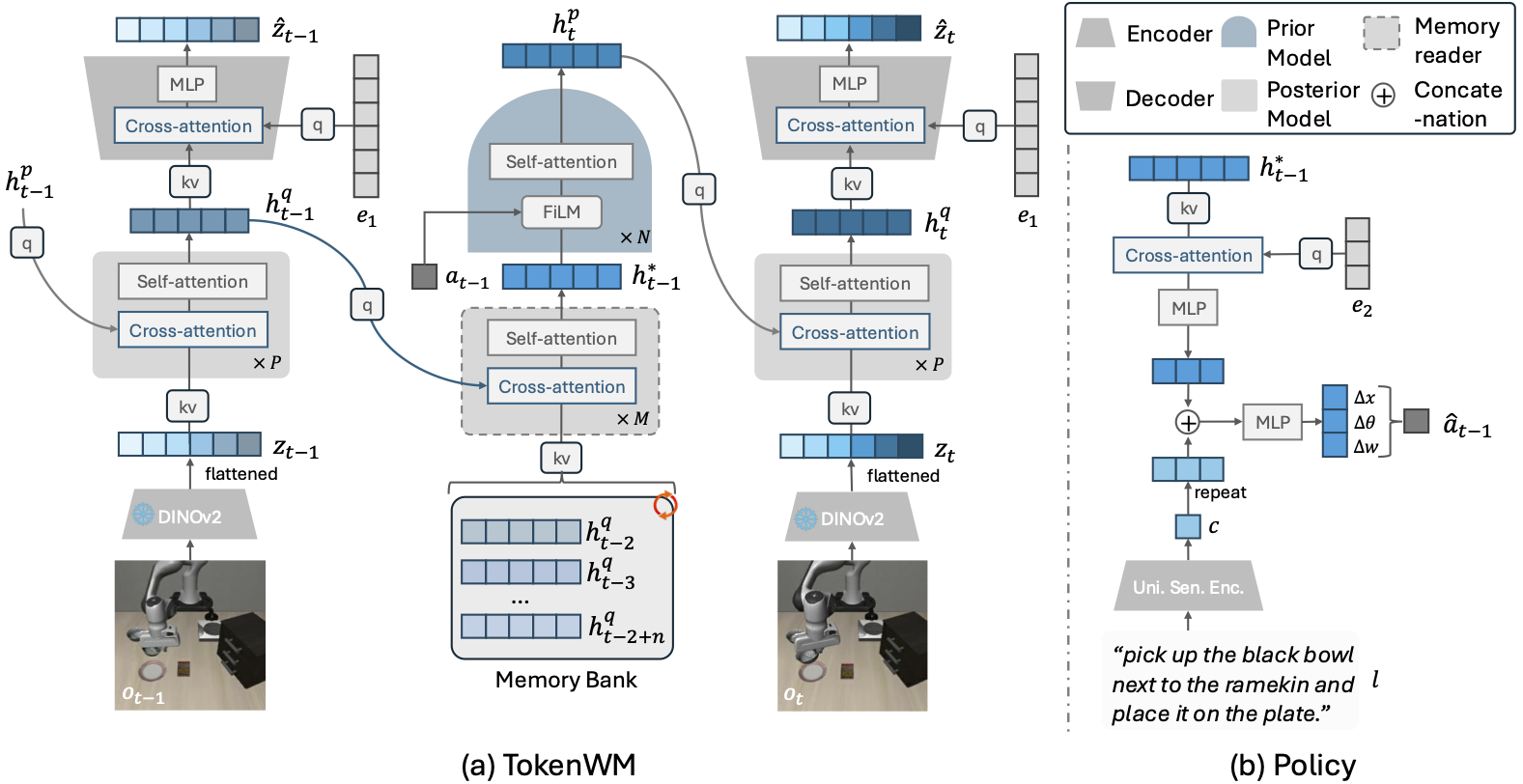
For a long horizon run, we believe world models play important roles in achieving AGI, as it learns the dynamics of actions and world states in the latent space. This mirrors human cognition, where observations are encoded into latent signals to infer actions for interacting with the world. In open-vocabulary robotic manipulation tasks, world models learn the causal relationships between language descriptions and object repositioning. We introduce TokenWM, a framework that constructs world states based on foundational visual features, thereby enhancing representational capacity and significantly improving manipulation performance.