SG-Bot: Object Rearrangement via Coarse-to-Fine Robotic Imagination on Scene Graphs
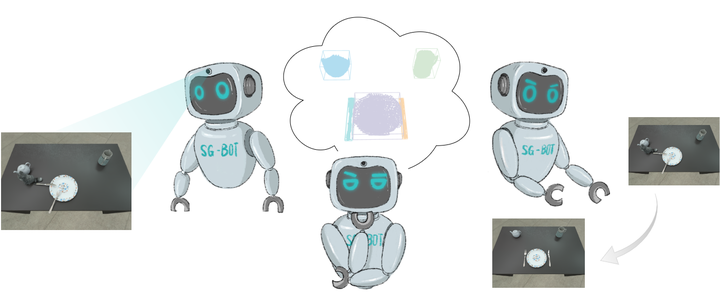 SG-Bot workflow. SG-Bot designs a three-fold procedure for robotic rearrangement.
SG-Bot workflow. SG-Bot designs a three-fold procedure for robotic rearrangement.Abstract
Object rearrangement is pivotal in robotic-environment interactions, representing a significant capability in embodied AI. In this paper, we present SG-Bot, a novel rearrangement framework that utilizes a coarse-to-fine scheme with a scene graph as the scene representation. Unlike previous methods that rely on either known goal priors or zero-shot large models, SG-Bot exemplifies lightweight, real-time, and user-controllable characteristics, seamlessly blending the consideration of commonsense knowledge with automatic generation capabilities. SG-Bot employs a three-fold procedure–observation, imagination, and execution–to adeptly address the task. Initially, objects are discerned and extracted from a cluttered scene during the observation. These objects are first coarsely organized and depicted within a scene graph, guided by either commonsense or user-defined criteria. Then, this scene graph subsequently informs a generative model, which forms a fine-grained goal scene considering the shape information from the initial scene and object semantics. Finally, for execution, the initial and envisioned goal scenes are matched to formulate robotic action policies. Experimental results demonstrate that SG-Bot outperforms competitors by a large margin.
Guangyao Zhai
(翟光耀)