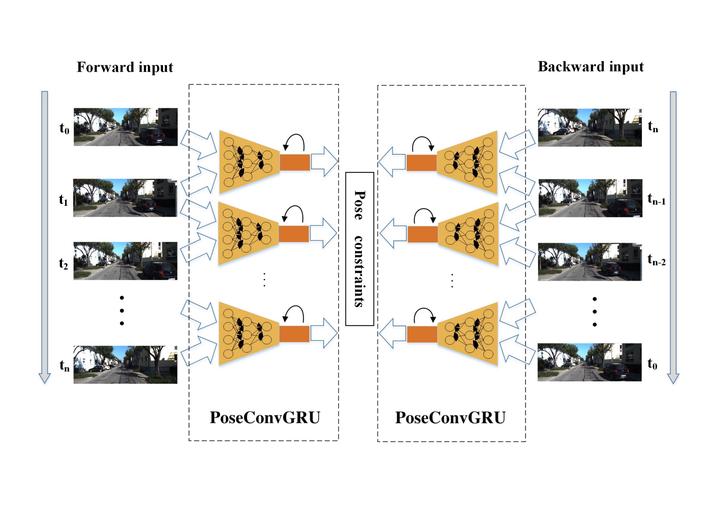
 The structure of whole framework presents a mirror-like symmetric construction.
The structure of whole framework presents a mirror-like symmetric construction.Abstract
Visual ego-motion estimation is one of the longstanding problems which estimates the movement of cameras from images. Learning based ego-motion estimation methods have seen an increasing attention since its desirable properties of robustness to image noise and camera calibration independence. In this work, we propose a data-driven approach of learning based visual ego-motion estimation for a monocular camera. We use an end-to-end learning approach in allowing the model to learn a map from input image pairs to the corresponding ego-motion, which is parameterized as 6-DoF transformation matrix. We introduce a two-module Long-term Recurrent Convolutional Neural Networks called PoseConvGRU. The feature-encoding module encodes the short-term motion feature in an image pair, while the memory-propagating module captures the long-term motion feature in the consecutive image pairs. The visual memory is implemented with convolutional gated recurrent units, which allows propagating information over time. At each time step, two consecutive RGB images are stacked together to form a 6-channel tensor for feature-encoding module to learn how to extract motion information and estimate poses. The sequence of output maps is then passed through the memory-propagating module to generate the relative transformation pose of each image pair. In addition, we have designed a series of data augmentation methods to avoid the overfitting problem and improve the performance of the model when facing challengeable scenarios such as high-speed or reverse driving. We evaluate the performance of our proposed approach on the KITTI Visual Odometry benchmark and Malaga 2013 Dataset. The experiments show a competitive performance of the proposed method to the state-of-the-art monocular geometric and learning methods and encourage further exploration of learning-based methods for the purpose of estimating camera ego-motion even though geometrical methods demonstrate promising results.
Guangyao Zhai
(翟光耀)